Artificial Intelligence Is Cracking Open the Vatican's Secret Archives
A new project untangles the handwritten texts in one of the world’s largest historical collections.

The Vatican Secret Archives is one of the grandest historical collections in the world. It’s also one of the most useless.
The grandeur is obvious. Located within the Vatican’s walls, next door to the Apostolic Library and just north of the Sistine Chapel, the VSA houses 53 linear miles of shelving dating back more than 12 centuries. It includes gems like the papal bull that excommunicated Martin Luther and the pleas for help that Mary Queen of Scots sent to Pope Sixtus V before her execution. In size and scope, the collection is almost peerless.
That said, the VSA isn’t much use to modern scholars, because it’s so inaccessible. Of those 53 miles, just a few millimeters’ worth of pages have been scanned and made available online. Even fewer pages have been transcribed into computer text and made searchable. If you want to peruse anything else, you have to apply for special access, schlep all the way to Rome, and go through every page by hand.
But a new project could change all that. Known as In Codice Ratio, it uses a combination of artificial intelligence and optical-character-recognition (OCR) software to scour these neglected texts and make their transcripts available for the very first time. If successful, the technology could also open up untold numbers of other documents at historical archives around the world.
OCR has been used to scan books and other printed documents for years, but it’s not well suited for the material in the Secret Archives. Traditional OCR breaks words down into a series of letter-images by looking for the spaces between letters. It then compares each letter-image to the bank of letters in its memory. After deciding which letter best matches the image, the software translates the letter into computer code (ASCII) and thereby makes the text searchable.
This process, however, really only works on typeset text. It’s lousy for anything written by hand—like the vast majority of old Vatican documents. Here’s an example from the early 1200s, written in what’s called Caroline minuscule script, which looks like a mix of calligraphy and cursive:

The main problem in this example is the lack of space between letters (so-called dirty segmentation). OCR can’t tell where one letter stops and another starts, and therefore doesn’t know how many letters there are. The result is a computational deadlock, sometimes referred to as Sayre’s paradox: OCR software needs to segment a word into individual letters before it can recognize them, but in handwritten texts with connected letters, the software needs to recognize the letters in order to segment them. It’s a catch-22.
Some computer scientists have tried to get around this problem by developing OCR to recognize whole words instead of letters. This works fine technologically—computers don’t “care” whether they’re parsing words or letters. But getting these systems up and running is a bear, because they require gargantuan memory banks. Rather than a few dozen alphabet letters, these systems have to recognize images of thousands upon thousands of common words. Which means you need a whole platoon of scholars with expertise in medieval Latin to go through old documents and capture images of each word. In fact, you need several images of each, to account for quirks in handwriting or bad lighting and other variables. It’s a daunting task.
In Codice Ratio sidesteps these problems through a new approach to handwritten OCR. The four main scientists behind the project—Paolo Merialdo, Donatella Firmani, and Elena Nieddu at Roma Tre University, and Marco Maiorino at the VSA—skirt Sayre’s paradox with an innovation called jigsaw segmentation. This process, as the team recently outlined in a paper, breaks words down not into letters but something closer to individual pen strokes. The OCR does this by dividing each word into a series of vertical and horizontal bands and looking for local minimums—the thinner portions, where there’s less ink (or really, fewer pixels). The software then carves the letters at these joints. The end result is a series of jigsaw pieces:

By themselves, the jigsaw pieces aren’t tremendously useful. But the software can chunk them together in various ways to make possible letters. It just needs to know which groups of chunks represent real letters and which are bogus.
To teach the software this, the researchers turned to an unusual source of help: high schoolers. The team recruited students at 24 schools in Italy to build the projects’ memory banks. The students logged onto a website, where they found a screen with three sections:
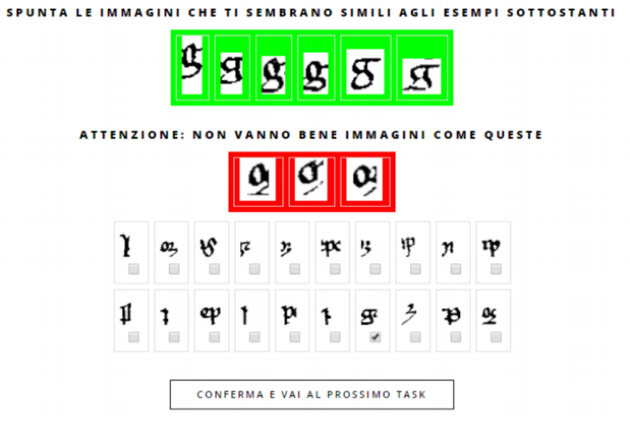
The green bar along the top contains nice, clean examples of letters from a medieval Latin text—in this case, the letter g. The red bar in the middle contains spurious examples of g, what the Codice scientists call “false friends.” The grid at the bottom is the meat of the program. Each of the images there is composed of a few jigsaw pieces that the OCR software chunked together—its guess at a plausible letter. The students then judged the OCR’s efforts, telling it which guesses were good and which were bad. They did so by comparing each image to the platonically perfect green letters and clicking a checkbox when they saw a match.
Image by image, click by click, the students taught the software what each of the 22 characters in the medieval Latin alphabet (a–i, l–u, plus some alternative forms of s and d) looks like.
The setup did require some expert input: Scholars had to pick out the perfect examples in green, as well as the false friends in red. But once they did this, there was no more need for them. The students didn’t even need to be able to read Latin. All they had to do is match visual patterns. At first, “the idea of involving high-school students was considered foolish,” says Merialdo, who dreamed up In Codice Ratio. “But now the machine is learning thanks to their efforts. I like that a small and simple contribution by many people can indeed contribute to the solution of a complex problem.”
Eventually, of course, the students stepped aside as well. Once they’d voted yes on enough examples, the software started chunking jigsaw pieces together independently and judging for itself what letters were there. The software itself became an expert—it became artificially intelligent.
At least, sort of. It turned out that chunking jigsaw pieces into plausible letters wasn’t enough. The computer still needed additional tools to untangle the knots of handwritten text. Imagine you’re reading a letter, and you come across this line:
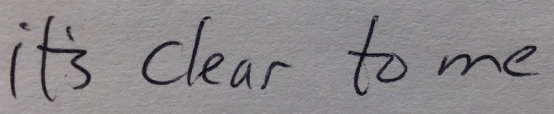
Is it “clear” to them or “dear” to them? Hard to say, since the strokes that make up “d” and “cl” are virtually the same. OCR software faces the same problem, especially with a highly stylized script like Caroline minuscule. Try deciphering this word:
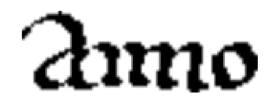
After running through different jigsaw combinations, the OCR threw up its hands. Guesses included aimo, amio, aniio, aiino, and even the Old MacDonald’s Farm–ish aiiiio. The word is anno, Latin for “year,” and the software nailed the a and o. But those four parallel columns in the middle flummoxed it.
To get around this problem, the In Codice Ratio team had to teach their software some common sense—practical intelligence. They found a corpus of 1.5 million already-digitized Latin words, and examined them in two- and three-letter combinations. From this, they determined which combinations of letters are common, and which never occur. The OCR software could then use those statistics to assign probabilities to different strings of letters. As a result, the software learned that nn is far more likely than iiii.
With this refinement in place, the OCR was finally ready to read some texts on its own. The team decided to feed it some documents from the Vatican Registers, a more than 18,000-page subset of the Secret Archives consisting of letters to European kings, rulings on legal matters, and other correspondence.
The initial results were mixed. In texts transcribed so far, a full one-third of the words contained one or more typos, places where the OCR guessed the wrong letter. If yov were tryinj to read those lnies in a bock, that would gct very aiiiioying. (The most common typos involved m/n/i confusion and another commonly confused pair: the letter f and an archaic, elongated form of s.) Still, the software got 96 percent of all handwritten letters correct. And even “imperfect transcriptions can provide enough information and context about the manuscript at hand” to be useful, says Merialdo.
Recommended Reading


Like all artificial intelligence, the software will improve over time, as it digests more text. Even more exciting, the general strategy of In Codice Ratio—jigsaw segmentation, plus crowdsourced training of the software—could easily be adapted to read texts in other languages. This could potentially do for handwritten documents what Google Books did for printed matter: open up letters, journals, diaries, and other papers to researchers around the world, making it far easier to both read these documents and search for relevant material.
That said, relying on artificial intelligence does have limitations, says Rega Wood, a historian of philosophy and paleographer (expert on ancient handwriting) at Indiana University. It “will be problematic for manuscripts that are not professionally written but copied by nonprofessionals,” she says, since the handwriting and letter shapes will vary far more in those documents, making it harder to teach the OCR. In addition, in cases where there’s only a small sample size of material to work with, “it is not only more accurate, but just as quick to make transcriptions without such technology.”
Pace Dan Brown, the “secret” in the Vatican Secret Archives’ name doesn’t refer to anything clandestine or conspiratorial. It merely means that the archives are the personal property of the pope; “private archives” would probably be a better translation of the original name, Archivum Secretum. Still, until recently, the VSA might as well have been secret to most of the world—locked away and largely inaccessible. “It is amazing for us to bring these manuscripts back to life,” Merialdo says, “and make their comprehension available to everybody.”